How to manage application logs in 2019? Piping it to a file? Dumping in in some Elasticsearch cluster? Shipping everything to “the cloud”? Well, all of those solutions suck.
-
… when piping logs to a file, they rot there. In many cases, this might be the only thing that you need to do with them and you are fine.
-
… when dumping a bunch of logs in Elasticsearch, you got a lot of work to do, I will come back to this later on. On the other hand, you will have a pretty neat solution.
-
… when shipping all your logs to the cloud, you need to put a serious amount of trust on the provider. In many cases this is not an option, among some other things I come to talk about.
If you have a lot of them, you might even transport and store your logs via some kafka cluster but in most cases, you neither have the amounts of logs nor the engineering team to build the solution.

The logging pipeline #
Lets imagine the following scenario: several applications, for example some nginx, a mail server, some docker-host and a customer facing booking solution are producing logs. These logs can for example be appended to a bunch of files, that get rotated when full.
If you have only one server and a limited amount of applications, this might be sufficient and is by far the simplest solution.
In the case of a server crash or if it gets compromized during an attack, the logs cannot be trust anymore or might be completely gone. This can possibly violate your obligations but at least makes it harder to do forensics in order to reconstruct, what happened.
So, instead of writing to a file, logs can sent to a syslog daemon running somewhere, in the simplest case on the same machine.
In the case of the booking system, writing to file might be the only supported solution and you are either not able or not allowed to change the program to work with syslog. In that case, it is common to forward the file contents along the other application logs via syslog. In this post, let us call them producers.
Syslog is a line based network protocol and therefore is easy to implement in applications. There exists an RFC specifying the layout of a syslog message but several applications, especially if they are shipped on a piece of hardware, have a very broad interpretation of how these logs should be structured. Therefore, in most of the cases, we need some sort of log parser, that transforms the syslog messages into an internal format and then forwards these messages.
Eventually, the log messages get stored somehow, typically either in a normal file, some kafka log or an elasticsearch index.
To cope with a crashed server and to facilitate management, it is generally desirable to aggregate logs in a central place. This centralized log management can be achieved by letting a syslog agent listen for logs and writing them to a file. More complex setups might involve message brokers, search-databases and so on, more on that later.
Logs, Metrics and Monitoring #
To further dive into the broad topic of logging, I first want to highlight its common applications and how it overlaps and differs from other areas like metrics and monitoring.
Logs #
Wikipedia defines logs and logging as follows:
In computing, a log file is a file that records either events that occur in an operating system or other software runs, or messages between different users of a communication software. Logging is the act of keeping a log. In the simplest case, messages are written to a single log file.
So, according to wiki, we keep a log of software events when logging. This is basically a diary of our software and we really want to read that diary after the software crashed or something went horribly wrong.
Many companies are required to store the logs of their computer systems for ridiculously long times, in some cases they might be required to delete personal data contained in the events within a short time span. therefore the systems that manage logs should be able to cope with different lifetime requirements of the data.
So, how does such a log message look like?The box below depicts a typical log message, generated by my nginx server, when the gitlab-runner was sending its heartbeat.
172.19.0.11 - - [17/Mar/2019:20:52:09 +0000] "POST /api/v4/jobs/request HTTP/1.1" 204 0 "-" "gitlab-runner 10.2.0 (10-2-stable; go1.8.3; linux/amd64)"
Such log messages are pretty worthless, since they occur every second and don’t contribute at all to finding bugs. Or do they? Lets assume these messages do not arrive within 5 seconds, then we can assume that something went wrong, perhaps was the TLS-Certificate rejected by gitlab or the runner crashed. So even the absence of a log message can indicate something important.
On the other hand, storing these messages for 10 years (as required in some industries) might be completely unnecessary. Therefore we need to take into account, what we want to do with each message.
Consider the following log message:
Mar 17 20:51:55 gateway systemd-logind[712]: New session 58 of user marco.
That one got created when I logged in via SSH to some gateway system. Such a message can be important after years, for example if you need to find out, who is responsible for some tax fraud, that was caused by some database alteration originating this exact session.
But can we distinguish which message to keep? Would it make sense to store the webserver log from above in the regard, that an attacker could try to cover his operations as such a daemon? Are we allowed to keep the user related login names, the originating IP and the time forever? Without precise domain knowledge it is nearly impossible to decide what logs are important, especially if the will only become important in the future. In such a case, it makes sense to store a few more than necessary (if we are allowed to) for a long time rather than reducing due to storage costs.
To summarize, we should be able to store large amounts of logs for a long time on cheap storage or smaller amounts on a fast to query medium since we either rarely never need them or don’t need them for long. Additionally, we need to be able to have a precise scheme on when to delete the logs to comply with applicable law.
Metrics #
When operating some software or hardware, we want to know how well it performs, how much the systems are loaded and be able to see if something is completely off-scale. These are gauges like requests per second, average system load or the 95th percentile of bandwidth used within the last minute. I personally regard metrics more of set of measures that display the current system state and perhaps provide a histogram to be able to observe the behavior over time. So software metrics are in that case like the gauges in a control room to have a readout of the current state plus a histogram like that of a ECG.
To be able to produce some histogram of a metric, say the CPU load, we need to store there values over time. There are great solutions for this, for example prometheus.
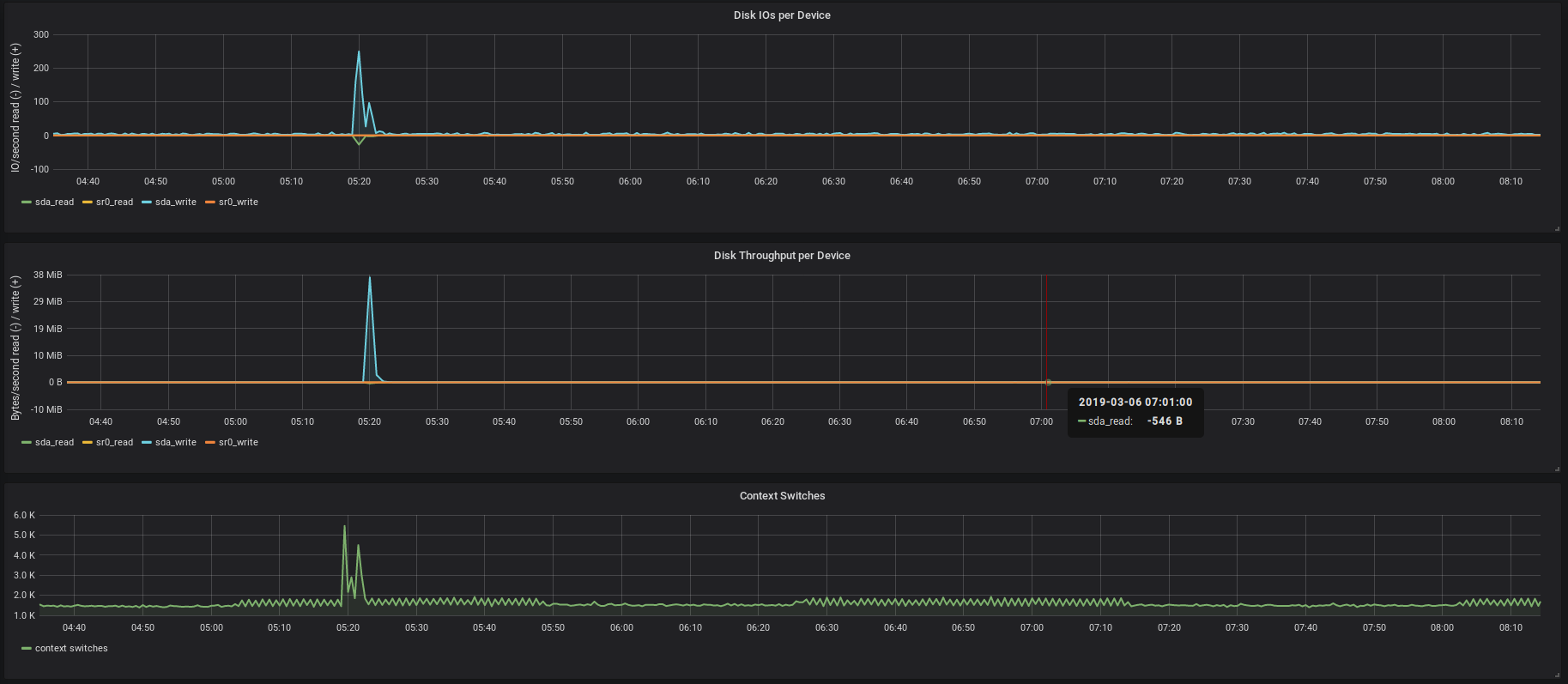
In the above image, there is a huge spike in the time series indicating some heavy load on the server. This might be an indicator of a problem with some software, some valid job that was running or an attack. In either case, it might be beneficial to refer to the logs of the server at that time. In this case, the metrics can help to identify the logs to look at. In other cases, it might be the logs that show weird behavior and the metrics might reveal that there was a job running hogging all available resources causing other actions to fail (for example the database-request, that timed out and produced a log entry).
So, why don’t we just regard metrics as logs and store them with the logs, we can then directly plot them from there and refer to the logs in the lines above or below. Well, do you want to store your system load for 10 years with the other logs? Therefore some time series databases provide decreasing resolution the further we go back in time. This means, we can see that over the past 10 years we have exponentially increased our bandwidth usage but won’t let you see every spike caused by a single download.
Monitoring #
In IT-Operations it is absolutely necessary to be able to detect failures and be alerted when they occur. A monitoring system might be one solution to approach this problem.
Some popular monitoring solutions try to achieve this by periodically querying a service and evaluating the result or time and alert the operations team if this is outside of the thresholds or completely absent.
For example, it is crucial for an email server to be able to receive emails at all time. A monitoring system might be able to identify problems like appearance in spam block lists, expired certificates or a crashed system by trying to send an email to an email account it controls on that server and notify operations if the email does not arrive within a set time interval.
Monitoring systems can monitor the metrics exposed by the metrics system and can check for the occurrence or absence of certain log messages but there might be better ways to approach this.
Conclusion #
All three aspects (logging, collecting metrics and monitoring) have some overlaps and can supplement each other. None the less, I doubt there is one single system that can or should handle all three sorts of data, even if people tend to try to achieve this again and again.
Current technologies #
In this section, I want to shortly go over some of the existing offerings and why I think they are not appropriate, for what I am looking for.
Rotting logfiles #
If you need to just store your logs and ideally never touch them again, then storing them in a file and moving those files to some offline storage might be amongst the simplest solutions for logging.
If you need some more value from your logs, a flat file might still be enough. It is possible to achieve pretty nice results with some awk and grep but the possibilities are limited. Normal flat files have the benefit that they can be read and analyzed by a multitude of applications what facilitates re-processing when requirements change and enable readability even if the original software might no longer be available.
Elasticsearch is hungry #
Most modern logging solutions use elasticsearch as a storage backend, for example the amazing Graylog that I have used at several companies to implement logging solutions. Elasticsearch originally is a search-database and organizes its data in indices that can be efficiently searched.
The downside of the elasticsearch based solutions are the requirements that elasticsearch brings in and the limited feature set of the open source solution.
Elasticsearch is quite resource hungry, it needs to have a lot of RAM, running an instance with less than 4GB available (and reserved by elasticsearch) does not make sense in anything but a test setting, as soon as you want to migrate or reindex data while the system is running.In the case of a tiny VPS I am not willing to sacrifice that much ressources just for logging.
The opensource solution has all the features necessary for the log management, none the less, one cannot control access to data in a fine grained manner, or even just require authentication on the whole database.
Side note: elastic co, the company behind elsaticsearch has some trouble with its open source community, since they are changing their licence (probably and absoluetly understandably because others are making a load of money from hosting elasticsearch without countributing anything back). But things like including X-Pack by default without clear notice in the installation instructions is considered a …. move:
By default, when you install Elasticsearch, X-Pack is installed.If you want to try all of the X-Pack features, you can start a 30-day trial. At the end of the trial period, you can purchase a subscription to keep using the full functionality of the X-Pack components.
I absolutely understand that the company has to make som money but this means that your installation will violate the licence or break after 30 days using it, gtfo, seriously. They even changed the docker image silently to include the xpack stuff, so if you just issued docker-compose pull, tough luck.
Brave new cloud #
Some cloud companies offer cloud based log management, what ranges from an hosted ELK stack to fully fledged distributed debugging environments. None the less, these offerings have several shortcomings. First of all, you need to entrust the service with your log data. If you already run services in the cloud, this might not be a problem, if you are in contrast a company that has exclusively on-premise hardware, there might be either laws forcing you to prevent data from leaving your network or your data might be that sensitive that hosted solutions are too much of a risk.
Another problem with hosted services are the pricing options, especially for high volume customers. Most offerings are billed per log entry or gigabyte per day. If you need to process a lot of logs but only want to filter out a small subset, that has to be stored, then you have to pay a lot of unnecessary bills for services you don’t use.
If you imagine a tiny company in the middle of the black forrest, that has a 10Mbit/s connection, dumping a load of logs to a cloudservice might not be possible or clogging the whole connection, if the logs arrive in a burst, some of them might even get lost.
Conclusion #
Logging for free currently isn’t a thing, if you want more features as provided by a flat file. If you are a company and need some nice features, you have either to pay a lot of money to some cloud company, elastic or splunk or throw away some logs you cannot afford and neglect the security of your setup. But if you have an engineering team at your hand, you can build the perfect solution four you use case based on open source code. On the other hand, if you only have a few personal servers and don’t get any money out of them, you might be missing a solution.